
Machine learning (ML) workloads require tremendous amounts of computing power. Of all the infrastructure components that scalable ML applications require, GPUs are the most critical. GPUs, with their parallel processing capabilities, have revolutionized domains like deep learning, scientific simulations, and high-performance computing. But not all ML workloads require the same amount of resources. Traditionally, ML scientists have had to pay for a full GPU regardless of whether they needed it.
In 2020, NVIDIA introduced Multi-Instance GPU (MIG) sharing. This feature partitions a GPU into multiple, smaller, fully isolated GPU instances. It is particularly beneficial for workloads that do not fully saturate the GPU’s compute capacity. It allows users to run multiple workloads in parallel on a single GPU to maximize resource utilization. This post shows how to use MIG on Amazon EKS.
NVIDIA Multi-Instance GPU
MIG is a feature of NVIDIA GPUs based on NVIDIA Ampere architecture. It allows you to maximize the value of NVIDIA GPUs and reduce resource wastage. Using MIG, you can partition a GPU into smaller GPU instances, called MIG devices. Each MIG device is fully isolated with its own high-bandwidth memory, cache, and compute cores. You can create slices to control the amount of memory and number of compute resources per MIG device.
MIG gives you the ability to fine tune the amount of GPU resources your workloads get. This feature provides guaranteed quality of service (QoS) with deterministic latency and throughput to ensure workloads can safely share GPU resources without interference.
NVIDIA has extensive documentation explaining the inner workings of MIG, so I won’t repeat the information here.
Using MIG with Kubernetes
Many customers I work with choose Kubernetes to operate their ML workloads. Kubernetes provides a powerful and scalable scheduling mechanism, making it easier to orchestrate workloads on a cluster of virtual machines. Kubernetes also has a vibrant community building tools like Kubeflow that make it easier to build, deploy, and manage ML pipelines.
MIG on Kubernetes is still an underutilized feature due its complexity. NVIDIA documentation is partly to be blamed here. While NVIDIA's documentation explains how MIG works extensively (albeit with a lot of repetition), it is lacking when it comes to providing resources like tutorials and example for MIG deployments and configurations on Kubernetes. What makes matters worse is that to use MIG on Kubernetes, you have to install a bunch of resources such as the NVIDIA driver, NVIDIA container runtime, and device plugins.
Thankfully, NVIDIA GPU Operator automates the deployment, configuration, and monitoring GPU resources in Kubernetes. It simplifies installing the components necessary for using MIG on Kubernetes. Its key features are:
- Automatic GPU driver installation and management
- Automatic GPU resource allocation and scheduling
- Automatic GPU monitoring and alerting
- Support for NVIDIA Container Runtime
- Support for NVIDIA Multi-Instance GPU (MIG)
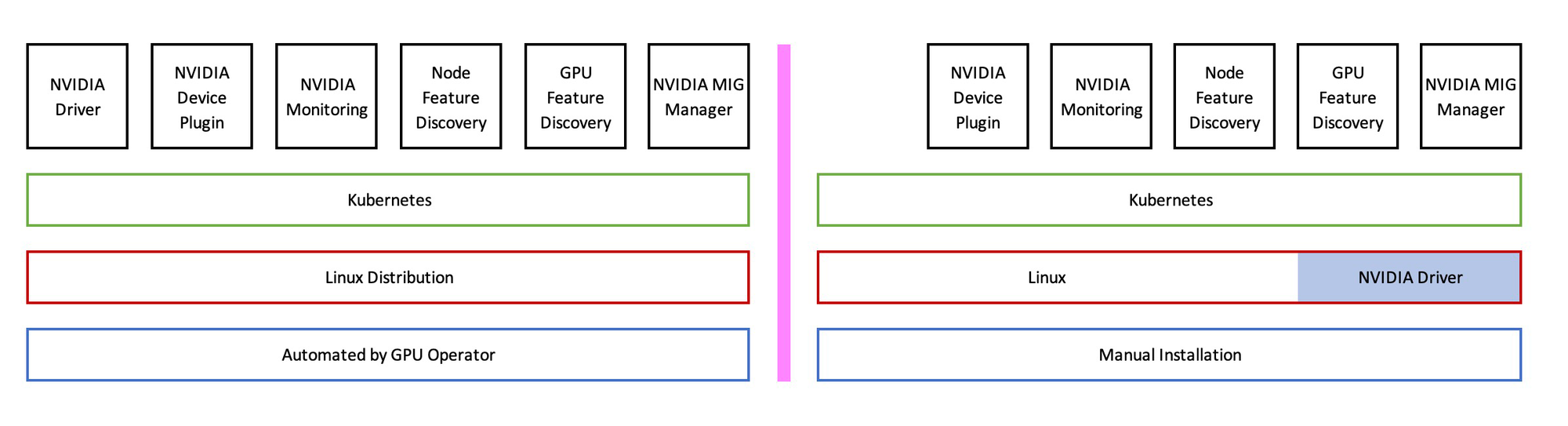
The operator installs the following components:
- NVIDIA device driver
- Node Feature Discovery. Detects hardware features on the node
- GPU Feature Discovery. Automatically generates labels for the set of GPUs available on a node
- NVIDIA DCGM Exporter. Exposes GPU metrics exporter for Prometheus leveraging NVIDIA DCGM
- Device Plugin. Exposes the number of GPUs on each nodes of your cluster, keeps track of the health of your GPUs, and runs GPU enabled containers in your Kubernetes cluster
- Device Plugin Validator. Runs a series of validations via
InitContainersfor each component and writes out results under/run/nvidia/validations - NVIDIA Container Toolkit
- NVIDIA CUDA Validator
- NVIDIA Operator Validator.Validates driver, toolkit, CDA, and NVIDIA Device Plugin
- NVIDIA MIG Manager. MIG Partition Editor for NVIDIA GPUs in Kubernetes clusters
NVIDIA GPU Operator on Amazon EKS
While NVIDIA GPU Operator makes it easy to use GPUs in Kubernetes, some of its components require newer versions of the Linux kernel and operating system. Amazon EKS provides a Linux AMI for GPU workloads that pre-installs NVIDIA drivers and container runtime. At the time of writing, this AMI provides Linux kernel 5.4. However, NVIDIA GPU Operator Helm Charts default are configured for Ubuntu or Centos 8. Therefore, making NVIDIA GPU Operator work on Amazon EKS is not as simple as executing:
helm install gpu-operator nvidia/gpu-operator
Walkthrough
Let’s start the walkthrough by installing NVIDIA GPU Operator. You’d need an EKS cluster with a node group made up of EC2 instances that come with NVIDIA GPUs (P4, P3, and G4 instances). Here’s an eksctl manifest if you’d like to create a new cluster for this walkthrough:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: p4d-cluster
region: eu-west-1
managedNodeGroups:
- name: demo-gpu-workers
instanceType: p4d.24xlarge
minSize: 1
desiredCapacity: 1
maxSize: 1
volumeSize: 200
I am going to use a P4d.24XL instance for this demo. Each P4d.24XL EC2 instance has 8 NVIDIA A100 Tensor core GPUs. Each A100 GPU has 40GB memory. By default, you can only run one GPU workload per GPU with each pod getting a 40GB GPU memory slice. This means you are limited to running 8 pods per instance.
Using MIG, you can partition each GPU to run multiple pods per GPU. On a P4d.24XL node with 8 A100 GPUs, you can create 7 5GB A100 slices per GPU. As a result, you can run 7*8 = 56 pods concurrently. Alternatively, you can create 24 pods with 10GB slices, or 16 pods with 20GB slices, or 8 pods with 20GB slices.
Since the latest versions of the components that the operator installs are incompatible with the current version of Amazon EKS optimized accelerated Amazon Linux AMI, I have manually set the versions of incompatible components to a version that works with the AMI.
Install NVIDIA GPU Operator:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \
&& helm repo update
helm upgrade gpuo \
nvidia/gpu-operator \
--set driver.enabled=true \
--set mig.strategy=mixed \
--set devicePlugin.enabled=true \
--set migManager.enabled=true \
--set migManager.WITH_REBOOT=true \
--set toolkit.version=v1.13.1-centos7 \
--set operator.defaultRuntime=containerd \
--set gfd.version=v0.8.0 \
--set devicePlugin.version=v0.13.0 \
--set migManager.default=all-balanced
View the resources created by GPU Operator:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-529vf 1/1 Running 0 20m
gpu-operator-9558bc48-z4wlh 1/1 Running 0 3d20h
gpuo-node-feature-discovery-master-7f8995bd8b-d6jdj 1/1 Running 0 3d20h
gpuo-node-feature-discovery-worker-wbtxc 1/1 Running 0 20m
nvidia-container-toolkit-daemonset-lmpz8 1/1 Running 0 20m
nvidia-cuda-validator-bxmhj 0/1 Completed 1 19m
nvidia-dcgm-exporter-v8p8f 1/1 Running 0 20m
nvidia-device-plugin-daemonset-7ftt4 1/1 Running 0 20m
nvidia-device-plugin-validator-pf6kk 0/1 Completed 0 18m
nvidia-mig-manager-82772 1/1 Running 0 18m
nvidia-operator-validator-5fh59 1/1 Running 0 20m
GPU Feature Discovery adds labels to the node that help Kubernetes schedule workloads that require a GPU. You can see the label by describing the node:
$ kubectl describe node
...
Allocatable:
attachable-volumes-aws-ebs: 39
cpu: 95690m
ephemeral-storage: 18242267924
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 1167644256Ki
nvidia.com/gpu: 8
pods: 250
...
Pods can request a GPU by specifying GPU in resources. Here's a sample pod manifest:
kind: Pod
metadata:
name: dcgmproftester-1
spec:
restartPolicy: "Never"
containers:
- name: dcgmproftester11
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
args: ["--no-dcgm-validation", "-t 1004", "-d 30"]
resources:
limits:
nvidia.com/gpu: 1
securityContext:
capabilities:
add: ["SYS_ADMIN"]
We won't create a pod that uses a full GPU because that will work out of the box. Instead, we'll create pods that use partial GPUs.
Creating MIG partitions on Kubernetes
NVIDIA provides two strategies for exposing MIG partitioned devices on a Kubernetes node. In single strategy, a node only exposes a single type of MIG devices across all GPUs. Whereas, Mixed strategy allows you to create multiple different sized MIG devices across all of a node's GPUs.

Using MIG single strategy, you can create similar sized MIG devices. On a P4d.24XL, you can create 56 1g.5gb slices, or 24 2g.10gb slices, or 16 3g.20gb slices, or a 1 4g.40gb or 7g.40gb slice.
Mixed strategy will allow you to create a few 1g.5gb along with a few 2g.10gb and 3g.20gb slices. It is useful when your cluster has workloads with varying GPU resource requirements.
Create MIG devices with single strategy
Let's create a single strategy and see how to use it with Kubernetes. NVIDIA GPU Operator makes it easy to create MIG partitions. To configure partitions, all you have to do is label the node. MIG manager runs as daemonset on all nodes. When it detects node labels, it will use mig-parted to create MIG devices.
Label a node to create 1g.5gb MIG devices across all GPUs (replace $NODE with a node in your cluster):
kubectl label nodes $NODE nvidia.com/mig.config=all-1g.5gb --overwrite
Two things will happen once you label the node this way. First, the node will no longer advertise any full GPUs and the nvidia.com/gpu label will be set to 0. Second, your node will advertise 56 1g.5gb MIG devices.
$ kubectl describe node $NODE
...
nvidia.com/gpu: 0
nvidia.com/mig-1g.5gb: 56
...
Please note that it may take a few seconds for the change to take effect. The node will have a label nvidia.com/mig.config.state=pending when the change is still in progress. Once MIG manager completes partitioning, the label will be set to nvidia.com/mig.config.state=success.
We can now create a deployment that uses MIG devices.
Create a deployment:
cat << EOF > mig-1g-5gb-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mig1.5
spec:
replicas: 1
selector:
matchLabels:
app: mig1-5
template:
metadata:
labels:
app: mig1-5
spec:
containers:
- name: vectoradd
image: nvidia/cuda:8.0-runtime
command: ["/bin/sh", "-c"]
args: ["nvidia-smi && tail -f /dev/null"]
resources:
limits:
nvidia.com/mig-1g.5gb: 1
EOF
You should now have a pod running that consumes 1x 1g.5gb MIG device.
$ kubectl get deployments.apps mig1.5
NAME READY UP-TO-DATE AVAILABLE AGE
mig1.5 1/1 1 1 1h
Let's scale the deployment to 100 replicas. Only 56 pods will get created because the node can only accommodate 56 1g.5gb MIG devices (8 GPUs * 7 MIG slices per GPU) .
Scale the deployment:
kubectl scale deployment mig1.5 --replicas=100
Notice that only 56 pods become available:
kubectl get deployments.apps mig1.5
NAME READY UP-TO-DATE AVAILABLE AGE
mig1.5 56/100 100 56 1h
Exec into one of the containers and run nvidia-smi to view allocated GPU resources.
kubectl exec <YOUR MIG1.5 POD> -ti -- nvidia-smi
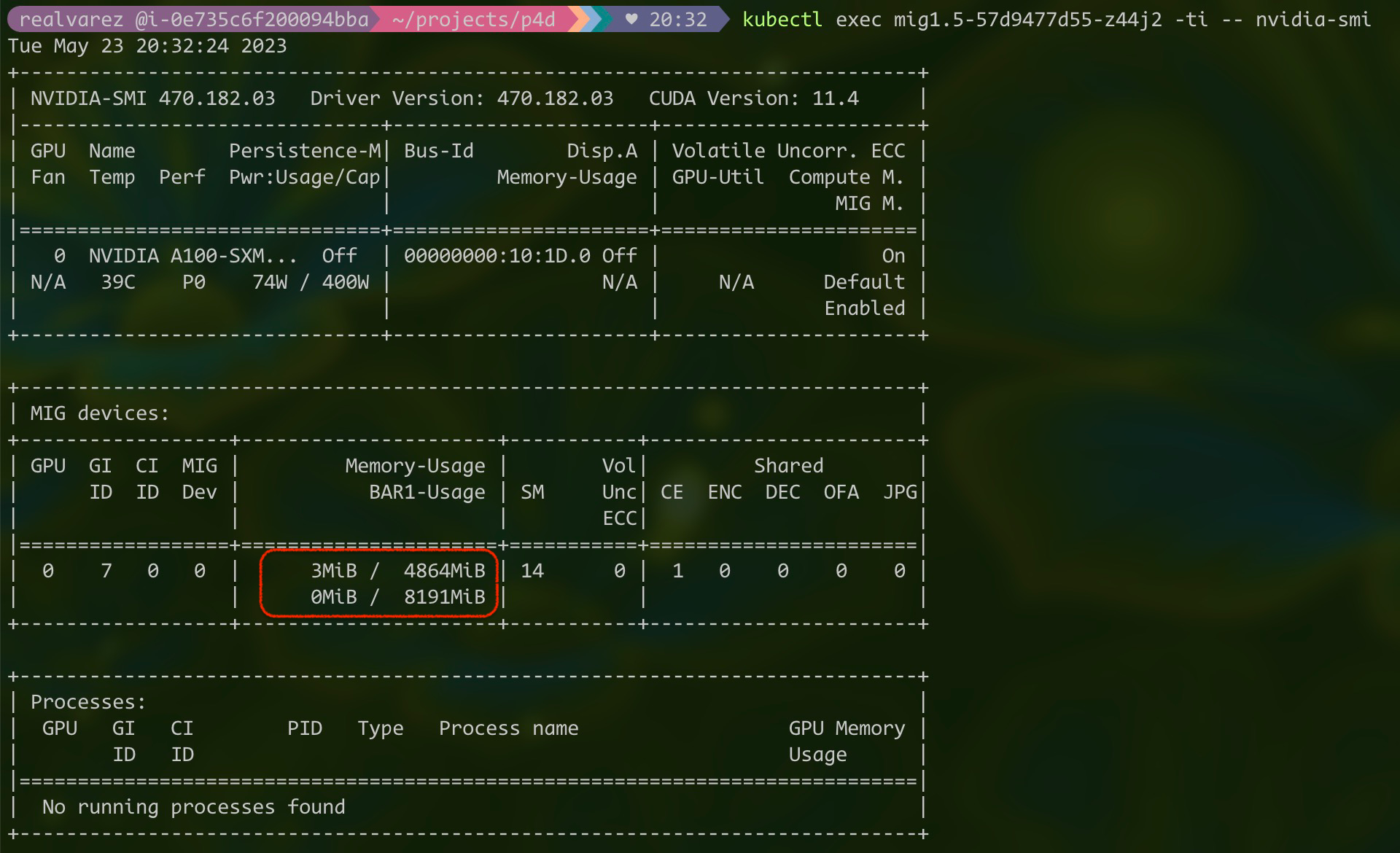
As you can see, this pod only has 5gb memory.
Let's scale the deployment down to 0:
kubectl scale deployment mig1.5 --replicas=0
Create MIG devices with mixed strategy
In single strategy, all MIG devices were 1g.5gb devices. Now let's slice the GPUs so that each node supports multiple MIG device configurations. MIG manager uses a configmap to store MIG configuration. When we labeled the node with all-1g.5gb, MIG partition editor uses the configmap to determine the partition scheme.
$ kubectl describe configmaps default-mig-parted-config
...
all-1g.5gb:
- devices: all
mig-enabled: true
mig-devices:
"1g.5gb": 7
...
This configmap also includes other profiles like all-balanced. The all-balanced profile creates 2x 1g.10gb, 1x 2g.20gb, and 1x 3g.40gb MIG devices per GPU. You can create your own custom profile by editing the configmap.
all-balanced MIG profile:
$ kubectl describe configmaps default-mig-parted-config
...
all-balanced:
- device-filter: ["0x20B010DE", "0x20B110DE", "0x20F110DE", "0x20F610DE"]
devices: all
mig-enabled: true
mig-devices:
"1g.5gb": 2
"2g.10gb": 1
"3g.20gb": 1
...
Let's label the node to use all-balanced MIG profile:
kubectl label nodes $NODE nvidia.com/mig.config=all-balanced --overwrite
Once the node has nvidia.com/mig.config.state=success label, describe the node and you'll see multiple MIG devices listed in the node:
$ kubectl describe node $NODE
...
nvidia.com/mig-1g.5gb: 16
nvidia.com/mig-2g.10gb: 8
nvidia.com/mig-3g.20gb: 8
...
With all-balanced profile, this P4d.24XL node can run 16x 1g.5gb, 8x 2g.20gb, and 8x 3g.20gb pods.
Let's test this out by creating two additional deployments. One with pods that use one 2g.10gb MIG device and another using 3g.10gb MIG device.
Create deployments:
cat << EOF > mig-2g-10gb-and-3g.20gb-deployments.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mig2-10
spec:
replicas: 1
selector:
matchLabels:
app: mig2-10
template:
metadata:
labels:
app: mig2-10
spec:
containers:
- name: vectoradd
image: nvidia/cuda:8.0-runtime
command: ["/bin/sh", "-c"]
args: ["nvidia-smi && tail -f /dev/null"]
resources:
limits:
nvidia.com/mig-2g.10gb: 1
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mig3-20
spec:
replicas: 1
selector:
matchLabels:
app: mig3-20
template:
metadata:
labels:
app: mig3-20
spec:
containers:
- name: vectoradd
image: nvidia/cuda:8.0-runtime
command: ["/bin/sh", "-c"]
args: ["nvidia-smi && tail -f /dev/null"]
resources:
limits:
nvidia.com/mig-3g.20gb: 1
EOF
Once pods from these deployments are running, scale all three deployments to 20 replicas:
kubectl scale deployments mig1.5 mig2-10 mig3-20 --replicas=20
Let's see how many of these replicas start running:
kubectl get deployments

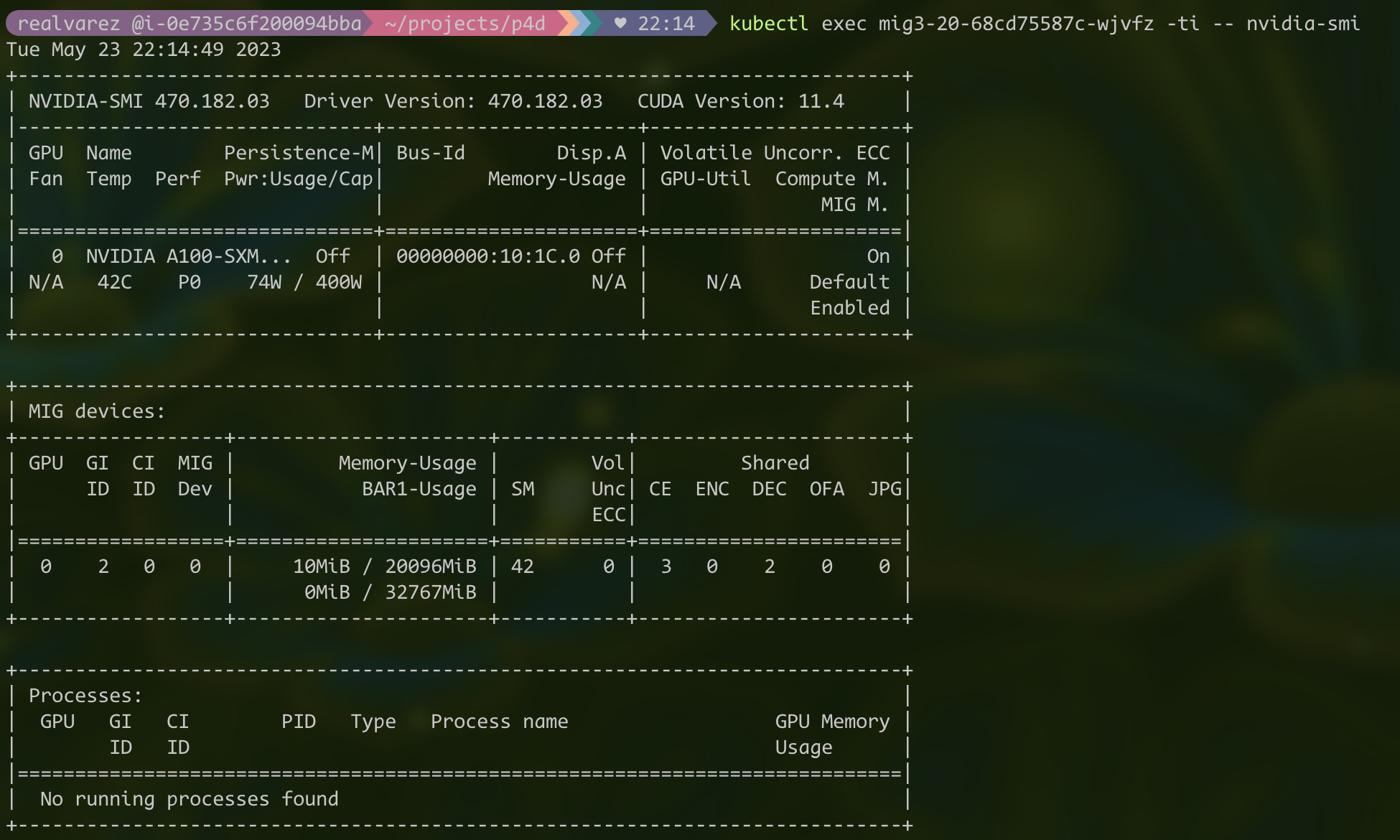
Let's see how much GPU memory a 3g.20gb pod receives:
kubectl exec mig3-20-<pod-id> -ti -- nvidia-smi
As expected, this pod has 20GB GPU memory allocated.
Cleanup
Delete the cluster and the node group:
eksctl delete cluster <CLUSTER_NAME>
Conclusion
This post shows how to partition GPUs using NVIDIA Multi-Instance GPU and using it with Amazon EKS. Using MIG on Kubernetes can be complex, but NVIDIA GPU Operator simplifies the process of installing MIG dependencies and partitioning.
By leveraging the capabilities of MIG and the automation provided by the NVIDIA GPU Operator, ML scientists can optimize their GPU usage, run more workloads per GPU, and achieve better resource utilization in their scalable ML applications. With the ability to run multiple applications per GPU and tailor the allocation of resources, you can optimize your ML workloads to achieve higher scalability and performance in your applications.
Resources
- Multi-Instance GPU — NVIDIA Cloud Native Technologies documentation
- NVIDIA Multi-Instance GPU User Guide :: NVIDIA Tesla Documentation
- NVIDIA GPU Operator Overview — NVIDIA Cloud Native Technologies documentation
- GPU Operator with MIG — NVIDIA Cloud Native Technologies documentation
- [External] Supporting MIG in Kubernetes - Google Docs
- [External] Challenges Supporting MIG in Kubernetes - Google Docs
- [External] Steps to Enable MIG Support in Kubernetes - Google Docs